
MAXQDAによる主題分析: ステップ・バイ・ステップガイド
MAXQDA Blog 翻訳版
Monday, May 30, 2022
圧倒的な量のデータに直面していますか?主題分析は解決策の一つとなります。
質的データ分析は、研究の初心者には一見とても敷居が高く見えるかもしれません。ノートいっぱいにフィールドノートを書き、何時間も様々な人と会話をし、何百もの画像や文書を調べなければならないのです。このような大量のデータを分析し、リサーチクエスチョンに答える2つか3つの箇条書きを作成することは、研究者にとって管理しやすいものといえるでしょうか。主題分析は、これを実現するための一つの方法です。主題分析とは、質的データ全体の意味のパターン、言い換えれば、テーマを特定し、整理し、洞察を提供する体系的なアプローチです(Braun & Clarke, 2012)。このブログ記事では、主題分析のステップと、主題分析に MAXQDA を使用する方法を紹介します。
- 主題分析フェイズ1: データに慣れる
- 主題分析フェイズ2: 初期コードを作成する
- 主題分析フェイズ3: テーマを探索する
- 主題分析フェイズ4: 潜在的なテーマを検討する
- 主題分析フェイズ5: テーマを定義し名づける
- 主題分析フェイズ6: 報告書を作成する
主題分析とは?
ここ数年、主題分析は社会科学で最もよく使われる分析アプローチの一つとなっています。Braunら(2019)は、内容分析と共通の歴史を持ち、1980年代までに質的データ分析アプローチとして健康・社会科学研究に登場し始めたと指摘しています。Google Scholarで”Thematic analysis”(引用符中の語)というキーワードで検索すると、370,000件以上の結果が表示されます。Braun and Clarke (2006)が執筆したUsing Thematic Analysis in Psychologyという主要論文だけでも、2022年5月までに126,000回以上引用されています。こうした簡単にアクセスできるデータは、このアプローチの人気の高さを示しています。この人気は、質的データを分析する研究者にモジュール性と柔軟性を与えることに関係していると思われます。しかし、それはまた、非常に体系的なプロセスであり、再帰的である必要があります。さらに主題分析は、研究者がデータセットに深く入り込むことを必要とします。Braun and Clarke (2006, 2012)は、このプロセスを体系化するために、質的研究者の指針となる6段階の主題分析の手順を提案しています。
研究プロジェクト
このブログ記事では、MAXQDAを使用して6段階の主題分析アプローチを進めた例として、私の最近の研究を紹介します。この質的研究では、オンラインで語学を教える大規模な公開オンライン コース (MOOC) で、外国語としての英語 (EFL) のオンライン専門能力開発の経験を説明するつもりでした。この研究は「How massive open online courses constitute digital learning spaces for EFL teachers: A netnographic case study “と題し、その名の通り、エスノグラフィーの手法を用い、2人のEFL教師のオンライン体験を質的ケースとして調査しました。2人の参加者をケースとする比較事例研究はデータ量が少ないように感じるかもしれなませんが、逆に、エスノグラフィー研究の典型的な特徴の一つは、研究者が調査対象の文化に長期間にわたって没頭する必要があることです。
研究データ
さらに、質的データのマルチモーダルな性質は、質的研究者にデータ収集の幅広い可能性を示しています。そこで私は、デジタル学習者日記(オンライン学習体験を通しての事例参加者の考察を含む)、半構造化インタビュー、参加者のオンラインフォーラムの投稿やオンラインコースでの似たような貢献を示すスクリーンショットなどを活用しました。再概念化された理論的・概念的枠組みを念頭に置くことなく、説明的に参加者の経験を調査することを意図し、帰納的コーディングと主題分析を用いました。この暫定的なプロセスを通して、MAXQDAのいくつかの機能が私の主題分析の各段階に役立っています。
主題分析の6フェイズ
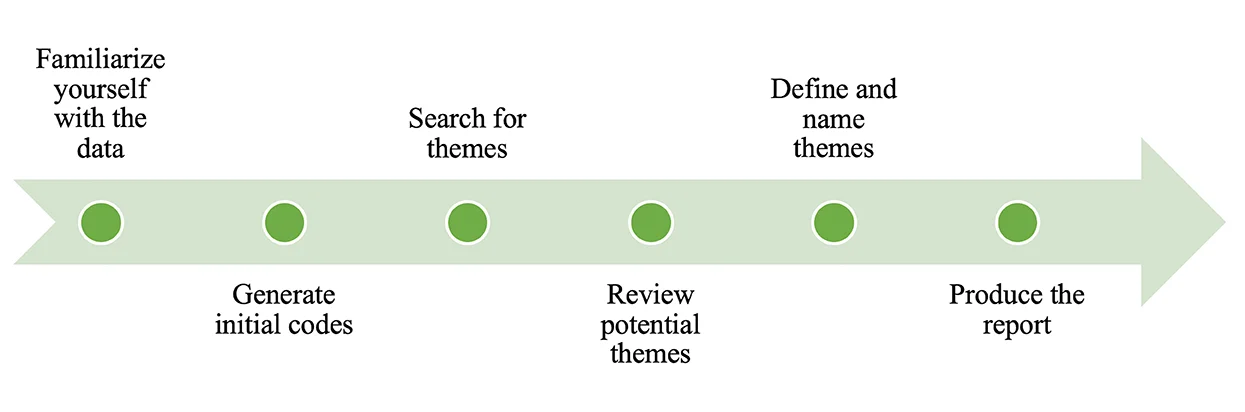
フェイズ1: データに慣れる
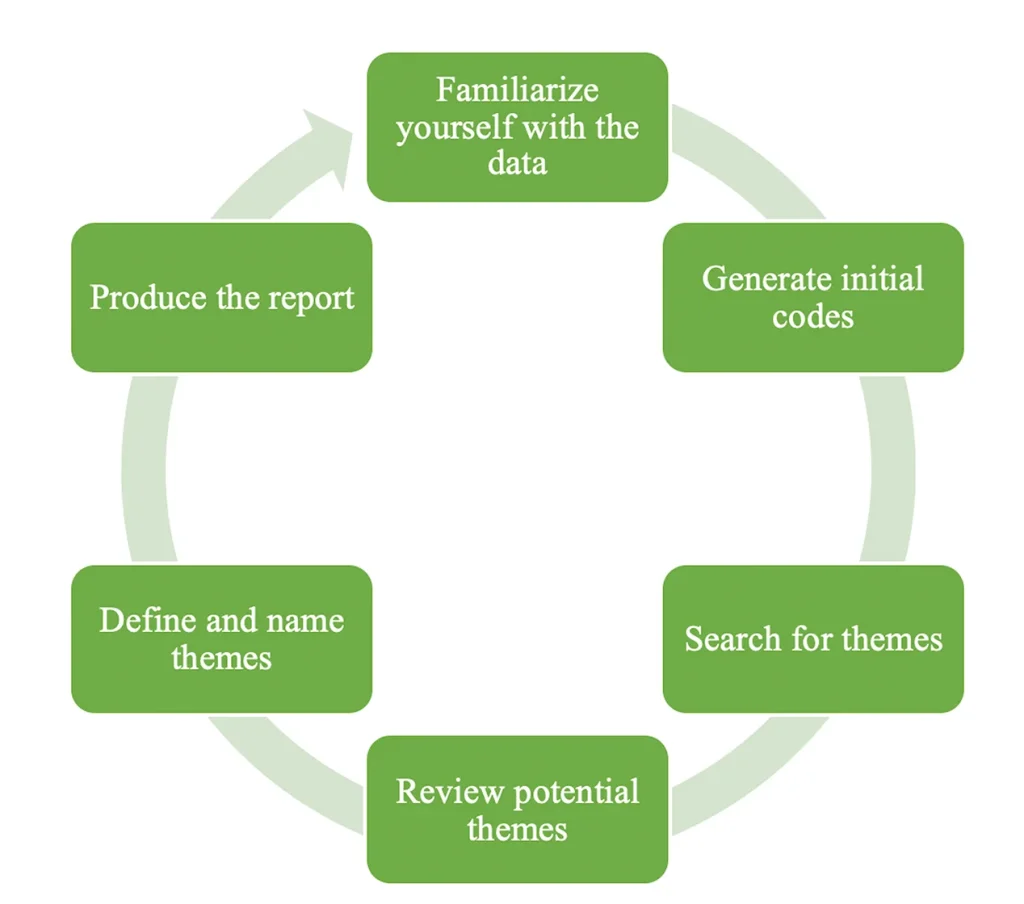
他の質的データ分析アプローチと同様に、データをテーマ別に分析する研究者は、まずデータに深く没頭することから始める必要があります。図1に示すように、6段階のフェイズはこのプロセスから始まります。Braun and Clarke (2006, 2012) は、このプロセスにおいて研究者は膨大な量のメモを書き留め、トランスクリプトに注釈をつけ、下線を引き、ハイライトし、さらに文書を(アン)グループ化しなければならないと強調しています。したがって、EFL教師のMOOC体験を調査する私の研究では、参加者のオーディオダイアリーやインタビュー記録を何度も聞き直す必要がありました。また、プラットフォーム上での彼らの交流や貢献を何度も何度も確認する必要がありました。
“ページに書かれた言葉の表面的な意味”を超えるために
Braun and Clarke (2006, 2012)によると、データセットに慣れ親しむ中で、心に留めておく必要がある特定の質問がありました: 私のケースの参加者は、MOOCの経験をどのように意味づけているのだろうか?彼らは自分の経験を解釈する際にどのような仮定と考察をするのか?その解釈から何が見えてくるのか?テーマ別分析の最初の段階であるにもかかわらず、これはすべての質的研究者にとって非常に負担の大きい作業です。しかし、この段階は「データをデータとして読み」始める、つまり「ページ上の言葉の表面の意味」(Braun & Clarke, 2012, p. 60, emphasis as original)を超えることができる、非常に重要な段階でもあるのです。
データのグループ化
MAXQDAは、様々なデータソースのグループ分けを試すことができ、多様なタイプのデータを扱うことができ、オーディオファイルを簡単に書き出すことができるので、データに慣れるために特に役に立ちました。
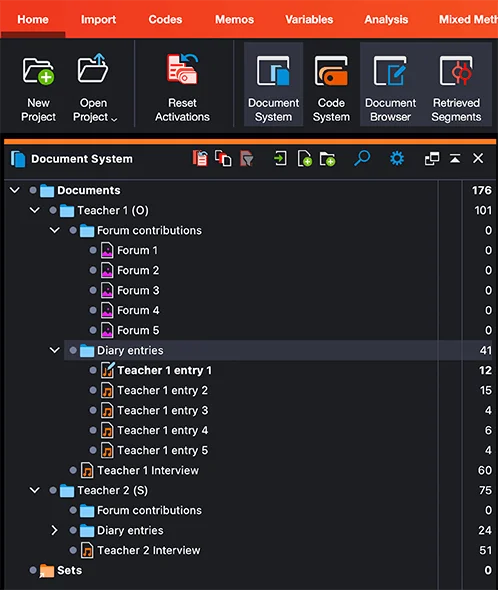
まず、MAXQDA の文書システムで、自分のデータをいろいろな方法でグループ化することを試しました。私の研究は、2 人の事例参加者(教師1と教師2、図 2 参照)の経験を報告する比較事例研究であるため、参加者ごとに データをグループ化することにしました。
データの書き起こし
次に、音声ファイルや画像など、異なるデータ形式をアップロードしました。異なるデバイスを使って日記を記録した2人のソースからオーディオ日記を収集したので、2 つの異なるデータ形式を扱わなければなりませんでした。MAXQDA では、これら 2 つのデータ形式のオーディオファイルを難なくアップロードし、 再生することができました。最後に、オーディオファイルの書き起こし機能を使ってみました。データを書き写す際にタイムスタンプを作成することで、オーディオファイルの特定の部分に戻って何度も聞くことができました。
フェイズ2:初期コードを作成する
主題分析におけるコーディング
文書システムがある程度整ったら、質的コーディングを開始します。Braun and Clarke(2012)によれば、コードは「分析の積み木」(p.61)であり、研究者が仮のリサーチクエスチョンに照らしてデータの意味を理解するのに役立つものです。Kuckartz and Rädiker(2019)によれば、研究者はデータの一部(セグメント)を選択しコードを割り当てるが、これは概念主導の演繹的アプローチとデータ主導の帰納的アプローチの2つの一般的な方法で行うことができます。主題分析ではコーディングは両方の方法で行うことができ、コード化されたセグメントは共起し、相互に関連する可能性があります。
新たに浮かび上がるコードに目を向ける
データに没頭していることを感じながら、初期コードを作成し始めました。分析レンズを形成する事前に概念化された理論的枠組みがないため、データ手動型、帰納的コーディングに依存し、出現したコードとコードグループを探しました。データセット全体のコーディングを完了しました。初期コード生成のプロセスで、私は MAXQDA の 2 つの機能、オープン・コーディングとメモを多用しました。MAXQDA でのオープンコーディングは、非常に直感的な体験でした。また、メモ は、以前にコーディングしたセグメントに対して新しいコードを作成するときに、自分の元の理由をさかのぼるのに役に立ちました。このメモは、文書システムで扱った22 個のファイルにわたって、以前に作成したコードを再利用する場合に役に立ちました。
第3段階:テーマを探索する
新たなテーマへの挑戦
主題分析に含まれるすべてのデータソースのコード化と再コード化に飽和感を覚えた後、コードからテーマへと移行しました。Braun and Clarke(2006)によると、テーマとは、リサーチクエスチョンに何らかの形で関連する「データセット内のパターン化された反応や意味」のことです(p.82)。テーマを探すことは、「テーマ探索」というフェイズ名でありながら、質的研究者がテーマを発見するのではなく、積極的にテーマを構築していく非常に能動的なプロセスです。Braun and Clarke(2012)はテーマを探す研究者を、埋もれている化石(=テーマ)を掘り起こし周囲の土を取り除く考古学者ではなく、彫刻の最終成果物に大きな影響を与えるような選択をする彫刻家に例えています。私の分析レンズはデータ主導型であり、リサーチクエスチョンは探索ではなく理解を目的としていたため、質的データ分析者である私のリサーチにはこのことが響いたのです。同時に、私は受動的な観察者ではなく、能動的な意味づけを行う必要がありました。私はデータとコミュニケーションを取り、テーマを構築しながら意味を理解する必要がありました。
視覚化でパターンを発見する
MAXQDAは、概念的なレベルでデータとコミュニケーションをとりながら、より積極的な分析者となるための多くの選択肢を提供してくれました。個人的には、視覚的なインプットがあると情報を統合しやすくなります。チャートや画像などの データの可視化によって、コードと新たなテーマ、文書と参加者の間の関係性を見ることができました。同様に、総括的なワークフローとパイプラインは、主題分析を含むほとんどの質的データ分析アプローチに必要とされる長いプロセスに自分自身を位置づけるのに役立ちます。この目的のために、私は MAXQDA の 3 つの特別な機能から大きな恩恵を受けています。コードマップ、MAXMaps、そしてQTT(Questions, Themes & Theories)です。
全体像を把握する
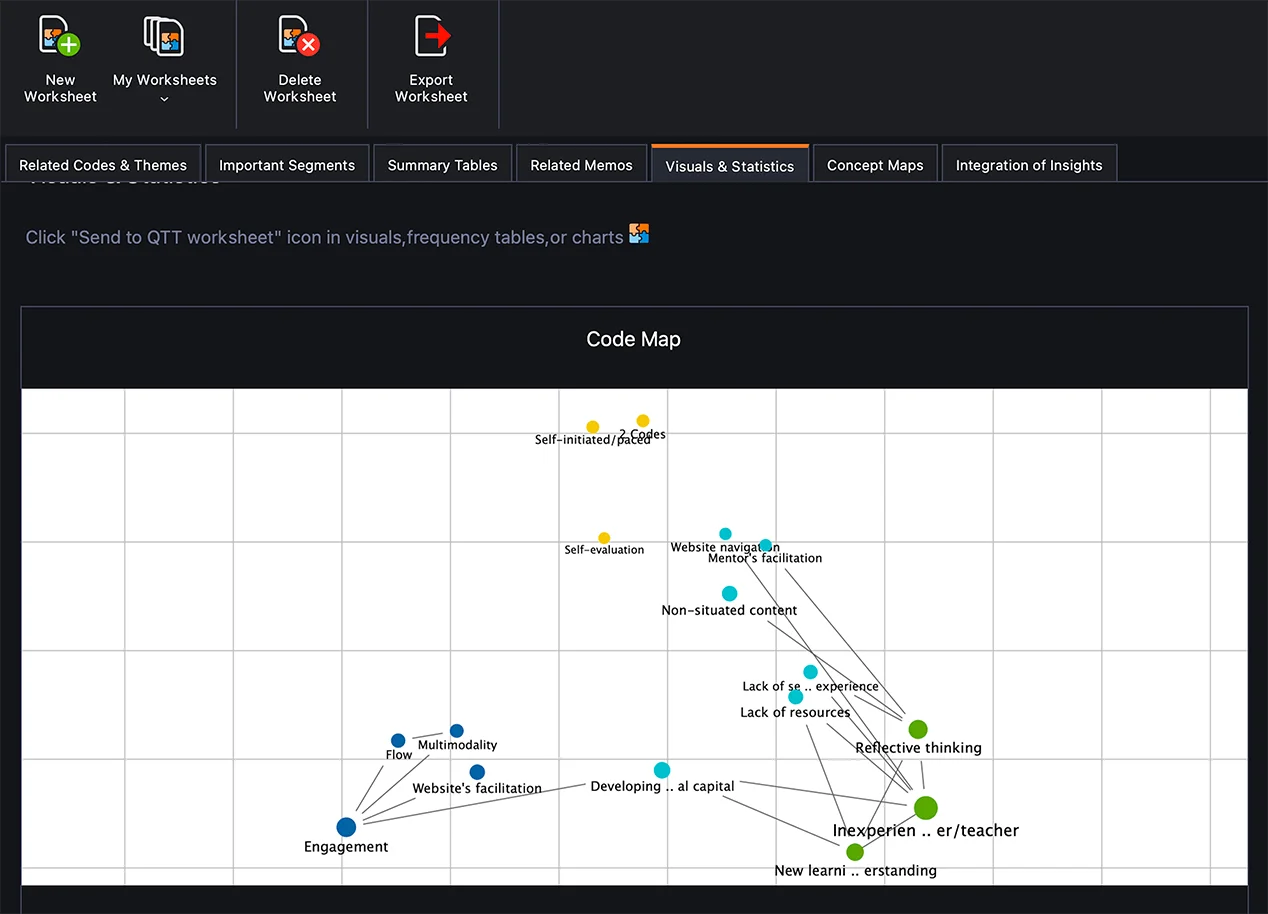
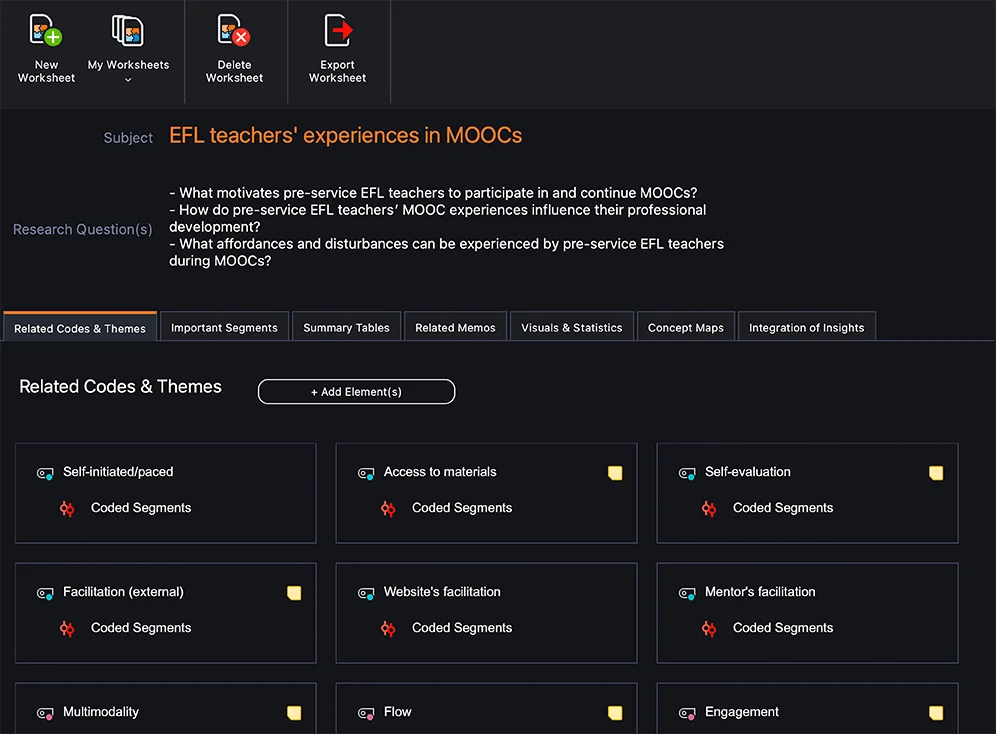
図 3 では、私がデータ分析に使用した QTT ワークシートの2つのスクリーンショットを示しました。まず第一に、MAXQDAでは研究者はコードマップを作成することができます。私はいつもコードマップから始めます。なぜなら、コードマップは作成にほとんど手間がかからず、没頭とコーディングの長い繰り返しのプロセスの後でメタポジションを取るのに役立つからです。しかし、先に説明したように、これはプロセスを開始する一つの方法であり、最後の方法であってはなりません。なぜなら、主題分析は、研究者が意味形成プロセスに積極的に関与することを要求するからです。
主題分析にQTTを活用
ここで、MAXQDA のもう一つの非常に重要な視覚化ツールについて説明します。MAXMapsです。MAXMaps は、コードと最初のテーマについて、刺激的なブレーンストーミングを 行うためのスペースを提供してくれました。このスペースで、私はコードや文書をアイコンとして取り出し、リンクや矢印でそれらの間の関係を作成したり、コードモデルを作成したりできました。最後に、MAXQDAの最新版では、QTT ワークシートを作成し、関連するコードやテーマ、コー ド化されたセグメント、そして作成したすべての視覚資料を1つのワークシートにインポートすることができました。このワークシート上で、疑問からテーマへ、さらにはその先の理論へと移行しようとするときに、常にリサーチクエスチョンやメモに立ち返ることができました。
第4段階:潜在的なテーマを検討する
この段階では、前の段階で構築されたテーマをレビューし、コードシステム全体、コード化されたセグメント、文書とクロスチェックします。テーマ、データ、リサーチクエスチョンは、関連性があり、整合性が取れている必要があります。そうすることで、研究者は、いくつかの新しいテーマを組み合わせて、包括的なテーマに到達することができます。一方、いくつかの新しいテーマは、非常に興味深く見えても、無関係であると判断される可能性があります。
主題分析のためのガイディング・クエスチョン
私は、Braun and Clarke (2012, p. 65)が提案したいくつかの重要な質問を参考にして潜在的なテーマを検討し、複数の出現したテーマを組み合わせて、包括的なテーマを構築しました。これらの指針的な質問を、以下のように私の研究状況に適合させました。
- このテーマは、私の2人のケース参加者、および/または、文書にまたがるパターンを示すものか?
- このテーマは、私の研究課題、および/または、EFL教師がMOOCsを用いた専門的学習において何を経験するかについて何かを教えてくれるのか?
- このテーマは、多くのコード化されたセグメントを含んでいるか、または除外しているか?
- このテーマが強いテーマであることを裏付けるに足るデータがあるか?
- このテーマは首尾一貫しているか、つまり、このテーマを支持するデータは類似の情報源(例えば、日記)から得られているか?
これらのガイディング・クエスチョンは私にとって有益なものでしたが、それでも、私はスマートな対処法を採用する必要がありました。
視覚化ツールで中心的なテーマを検出する
MAXQDA には、私をさらに導いてくれる他の視覚化ツールがあります。私は、コードと文書のマトリックスを利用して、最初のテーマが強力なものであるかどうか、そして、そこから関連する包括的なテーマを構築できるかどうかを検討し、決定しました。
まず、コード間の関係をさらに理解するために、コード間関係ブラウザを使用しました。例えば、このマトリックスから導き出された一つの含意は、私のケース参加者のエンゲージメントの感覚とMOOCプラットフォームのファシリテーションの間に強い関係があることです。このことから、私はコード化したセグメントに戻り、この関係からテーマを構築できるかどうか、またこの関係に関連する他のコード(例えば、フロー)があるかどうかを判断することにしました。
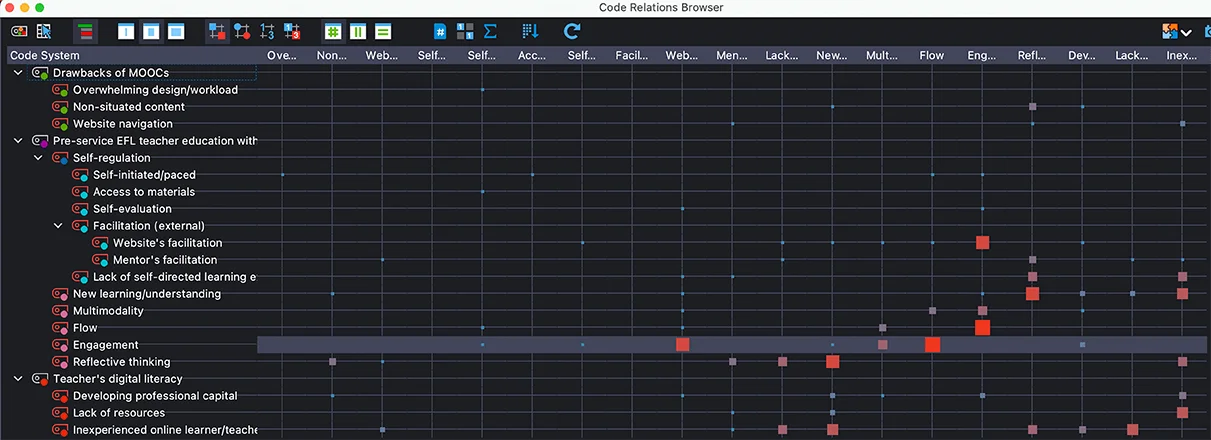
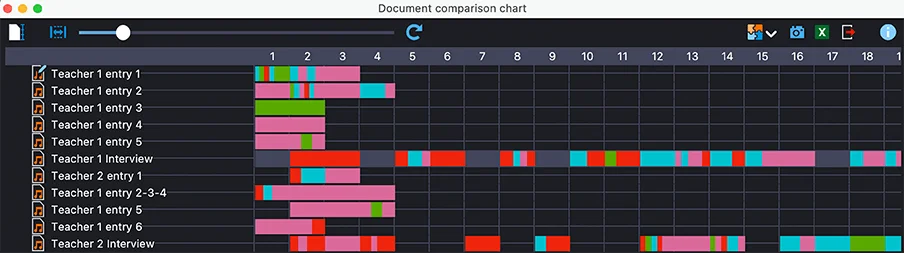
コード間関係ブラウザやマトリックスと同様に、文書比較チャートも、BraunとClarkeのガイディング・クエスチョンを使って、最初のコードを見直すのに役立ちました。私のコードシステム(図4の左側のコードシステムを参照)のコードに色をつけた後、すべてのオーディオダイアリーのエントリにピンクのブロックが含まれていることがわかり、これはケース参加者が何らかの学習経験(例えば、新しい理解、関与、反射、フロー、マルチモーダル学習など)を明らかにしたことを表しています。同様に、私のインタビューデータも、参加者が既存の、あるいは発展途上のデジタルリテラシーについて考察していることを示唆しています(赤色のセグメント)。
第5段階 テーマを定義し名づける
これは、主題分析のもう一つの段階であり、前の段階と密接に関連しています。主題分析を行う研究者は、出現したテーマをレビューし、包括的なテーマを構築する際に、これらの包括的なテーマが反復していないか、重複していないかを確認する必要があります(さもなければ、それらを組み合わせる必要があるかもしれません)。また、Braun and Clarke(2012)は、研究者がテーマを定義し、命名するのは、それが特異な焦点を持ち、リサーチクエスチョンに応える場合に限ることを示唆しています。
QTTで焦点を合わせる
この段階では、QTTによってリサーチクエスチョンを常に念頭に置くことができ(図3参照)、次の4つの包括的なテーマに到達しました:(1)MOOCの自己規制効果、(2)オンライン教育の神秘化をもたらすオンライン学習経験の提供、(3)EFL現職教師の教師キャリアへの準備、(4)MOOCデザインにおける大量性と非定位による限界。
コードによるテーマの定義
MAXQDA のコードシステムは、このプロセスをさまざまな方法でサポートしています。特に、テーマに色をつける機能を利用しました。同様に、蛍光ペンとお気に入りのコードも、このプロセスを支援します。もう一つの簡単にできることは、コードシステム全体にわたってコードをドラッグ&ドロップし、サブコー ドをグループ化するためのコードノードを作れることです。これにより、コードファミリーを作成することができ、テーマの定義や命名を行う際に役立ちました。
第6段階 報告書を作成する
主題分析の最終段階は、包括的なテーマと関連するコード付きセグメントを手に入れたハッピーエンドのように見えるかもしれませんが、実はとても厄介なものでした。すべての質的研究アプローチと同様に、主題分析は非常に再帰的なプロセスであり、量的研究とは異なり、前のフェイズが終了して初めてフェイズが開始されるようなフェイズゲート・プロセスを持ちません。それどころか、主題分析のレポートでは、データ分析の最初のフェイズにさえも戻る必要がありました。
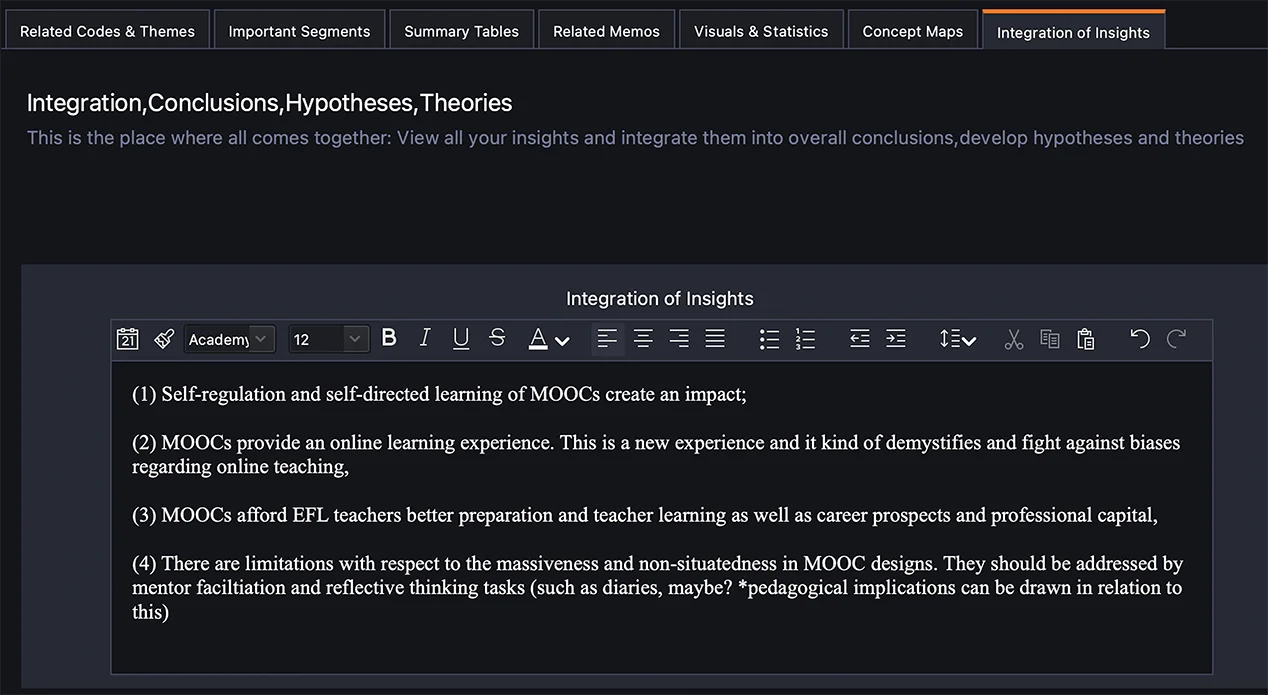
すべてをひとつにする
このように、何度も行ったり来たりすることで、私は自分のデータに没頭することができました。なぜなら、主題分析レポートは、「私の」分析に基づく「私の」データについて、(読者にとって)「説得力のある物語」を含むべきだからです(Braun & Clarke, 2012, p.69)。QTTワークシートの最後のページ(図6参照)で、私はすべての包括的なテーマをリサーチクエスチョンと一緒にまとめ、それらを洞察に統合し、結論を導き、仮説を展開しました。また、コード付きセグメントを重要セグメントタブに取り出し、包括的なテーマとリンクさせるという機能もよく使いました。これは、研究論文の発見と考察のセクションを書き出すときにも役立ちました。
結論
質的データ分析、特に主題分析は、研究者がデータの意味を理解し、そこから仮説を合成するために多くの時間を費やす必要があり、大変な作業のように見えるかもしれません。ポイント&クリックのインターフェースでデータから切り離されたように感じる定量データ分析ソフトウェアとは異なり、質的データ分析ソフトウェアでは、データセットに没頭する方法があります。これは、質的研究を成功(そして有意義に)させるためにパラダイム的に非常に重要です。
MAXQDAで意味づけの再帰的サイクルを作る
主題分析は、研究者がデータに没頭することが必要なアプローチです。MAXQDAの多くの機能は、私が没頭するために大いに役立ちました。これらの機能により、私は「彫刻家」(Braun & Clarke, 2012)のように、石の塊から何かを生み出す過程で選択と決定を下すことができたのです。そのため、データ分析のプロセスにおいて、研究者である私自身が声を上げることが可能になったのです。このプロセスは、6段階アプローチを反射的なプロセスとして再認識する主題分析をめぐる最近の話題を生み出しました(Braun et al., 2019; Braun & Clarke, 2019, 2020を参照)。私の主題分析におけるMAXQDAのもう一つの有用なアフォーダンスは、主題分析の段階を戻したり進めたりできることです。このアフォーダンスによって、私の主題分析は、図1のようにテーマ別分析のフェイズを線形に並べるだけのフェイズゲート・プロセスではなく、図7のような本当の再帰的プロセスだと感じられるようになったのです。このようにして、私は、これらのフェイズが互いにどのようにコミュニケートし、意味形成の連続的かつ再帰的なサイクルを作り出しているかを見ることができました。
注:この投稿は、MAXQDAのユーザーとしての私の研究経験に基づいています。上記の研究プロジェクトは報告済みで、現在、The Journal of Teaching English with Technologyの2022年6月号に掲載されるべくプレス中です。
References
- Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77–101. https://doi.org/10.1191/1478088706qp063oa
- Braun, V., & Clarke, V. (2012). Thematic analysis. In H. Cooper (Ed.), APA handbook of research methods in psychology Vol 2: Research designs (Vol. 2, pp. 57–71). American Psychological Association. https://doi.org/10.1037/13620-004
- Braun, V., & Clarke, V. (2019). Reflecting on reflexive thematic analysis. Qualitative Research in Sport, Exercise and Health, 11(4), 589–597. https://doi.org/10.1080/2159676X.2019.1628806
- Braun, V., & Clarke, V. (2020). One size fits all? What counts as quality practice in (reflexive) thematic analysis? Qualitative Research in Psychology, 00(00), 1–25. https://doi.org/10.1080/14780887.2020.1769238
- Braun, V., Clarke, V., Hayfield, N., & Terry, G. (2019). Thematic analysis. In P. Liamputtong (Ed.), Handbook of research methods in health social sciences (pp. 843–860). Springer. https://doi.org/10.1007/978-981-10-5251-4_103
- Kuckartz, U., & Rädiker, S. (2019). Analyzing Qualitative Data with MAXQDA. Text, Audio, and Video. Springer. https://doi.org/10.1007/978-3-030-15671-8
About the Author

Özgehan Uştuk, Ph.D. is a professional MAXQDA trainer and and currently works at Balikesir University, Turkey as a researcher, language teacher, and teacher educator. His research interests include language teacher education, practitioner inquiry, psychology of language teaching and learning, language teacher identity, emotions, and tensions. He is the incoming chair of the Research Professional Council in the TESOL International Association
- この投稿は掲載元と著者の許可を得て、MAXQDA Blogより日本語訳したものです。
- 詳細は原文Thematic Analysis with MAXQDA: Step-by-Step Guideを確認いただくことをお勧めします。



{kind=link}