
NVivo Transcriptionを使ってみる -3
音声認識を使用した自動音声文字起こしサービス、NVivo Transcriptionについて概要とデモデータで使用してみた体験を以前掲載しました。その後、実際のインタビュー録音をNVivo Transcriptionで書き起こしてみる機会がありましたので、今回は新たに気づいた点を紹介します。
前回も書きましたが、精度は音質などの条件に左右されます。以下はあくまでも今回使用したファイルの場合の体験で、すべてのケースに当てはまるとは限りませんのでご了承ください。
- 参考
- NVivo Transcriptionを使ってみる -1: 概要
- NVivo Transcriptionを使ってみる -2: デモデータで試用して気づいたことなど
ファイルサイズの制限
今回使用したファイルは、3名が話している約130分間の音声です。
NVivo Windowsに音声ファイルをインポートし、NVivo Transcriptionにアップロードしようとしたところ、ファイルサイズが大きすぎるとのメッセージが表示されました。NVivoからシームレスに利用できるファイルサイズは「2GB未満かつ、2時間未満」とのことです。
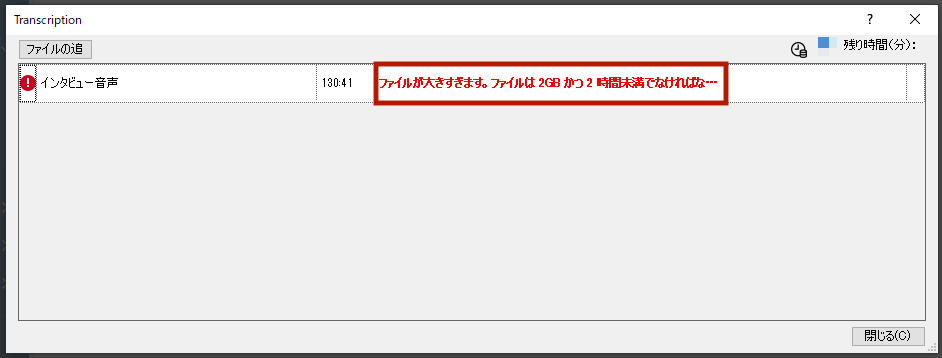
長時間のファイルを使用する場合は、以下いずれかの方法となりそうです。
- 方法1
- NVivo Transcriptionのサイトにファイルをアップロード
- トランスクリプトをダウンロード
- NVivo内の音声ファイルにトランスクリプト[行をインポート]
※手順はNVivo Transcriptionを使ってみる -2でも紹介しています
- 方法2
- 予めファイルを2時間未満に分割する
- NVivoに複数のファイル(それぞれ2時間未満)としてインポート→NVivo Transcription
方法2では、NVivoプロジェクト内で複数のファイルとして扱うことになるので、後の利便性を考えると方法1の方が使い勝手が良さそうです。
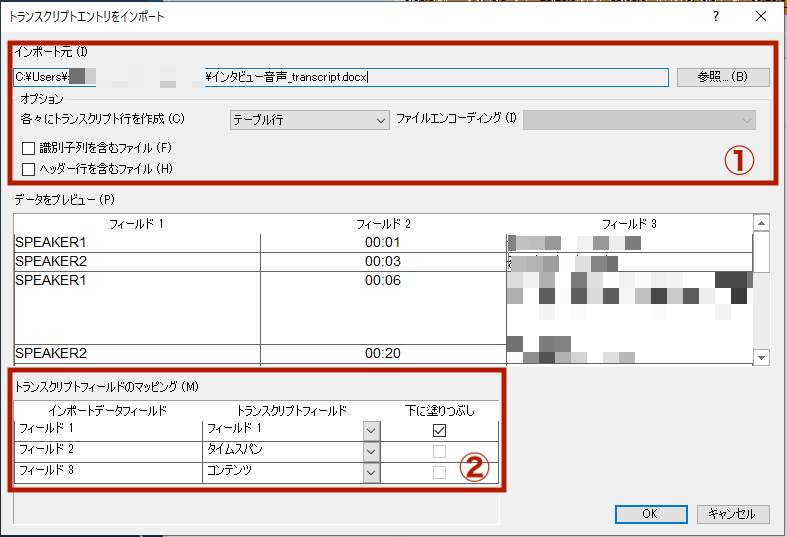
①ファイルと、トランスクリプト行の単位(ここではテーブル行)を指定
②プレビューを見ながらフィールドを割り当て
Tips – 上の図では話者名が「フィールド1」に割り当てられています。フィールド名を変更したい場合は、[ファイル]→[プロジェクトのプロパティ]→[音声/動画]タブで設定できます。または、同設定で前もって「スピーカー」というフィールドを作っておくと、[トランスクリプトフィールドのマッピング]で選択できるようになります。
話者の識別
NVivo Transcriptionは、話者変更を認識してSPEAKER1、SPEAKER2・・というように発言ごとに話者名を割り当ててくれます。今回の使用では、話者の識別はあまり当てにならない印象でした。
- 一つの発言が複数に分割されている
インポートしたトランスクリプトは1,548行(発言)。そこから音声を聞きながら発言ごとにまとめていったところ、最終的には350行(発言)となりました。発言が分割されることで、実際の5倍近い行数となってたことがわかります。 - 分割した分だけSPEAKERが増える
各発言にSPEAKERが割り振られるため、実際の話者は3名ですが、トランスクリプトにはSPEAKER8までありました。
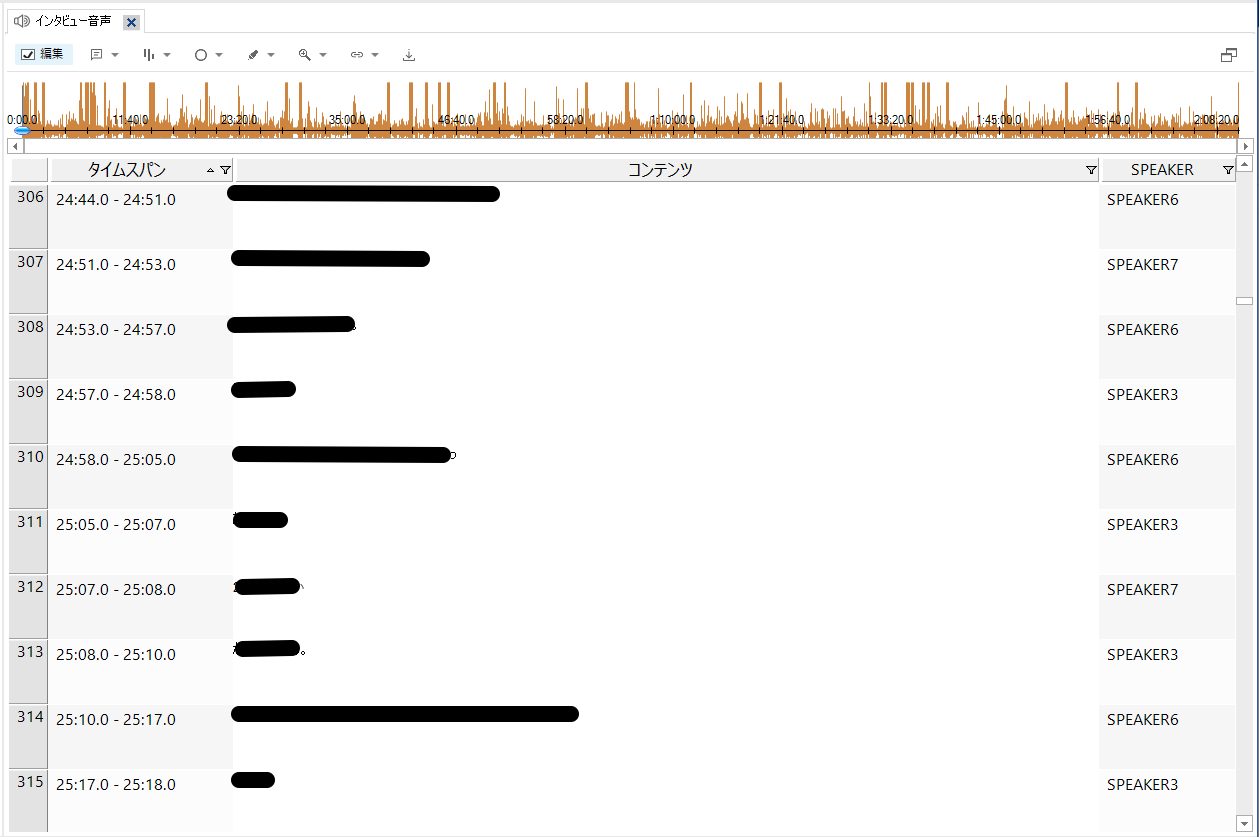
- 複数の発言が一つにまとめられてしまう
逆に、複数人の発言が1発言にまとめられている行も散見されました。間をあけず会話が進んでいる場合に特に多かった印象です。
話者の認識をどう行っているのかはわかりません。声の質、沈黙時間などで判断しているのかという気がしますが、確認はできておりません。もし音声の特徴が判断基準になっているのであれば、今回のファイルは男性3名でしたので、余計に認識しづらかった可能性もあります。
トランスクリプトの修正
音声を確認し行をマージしたり、分割したりしながら、NVivoでトランスクリプトを修正しました。
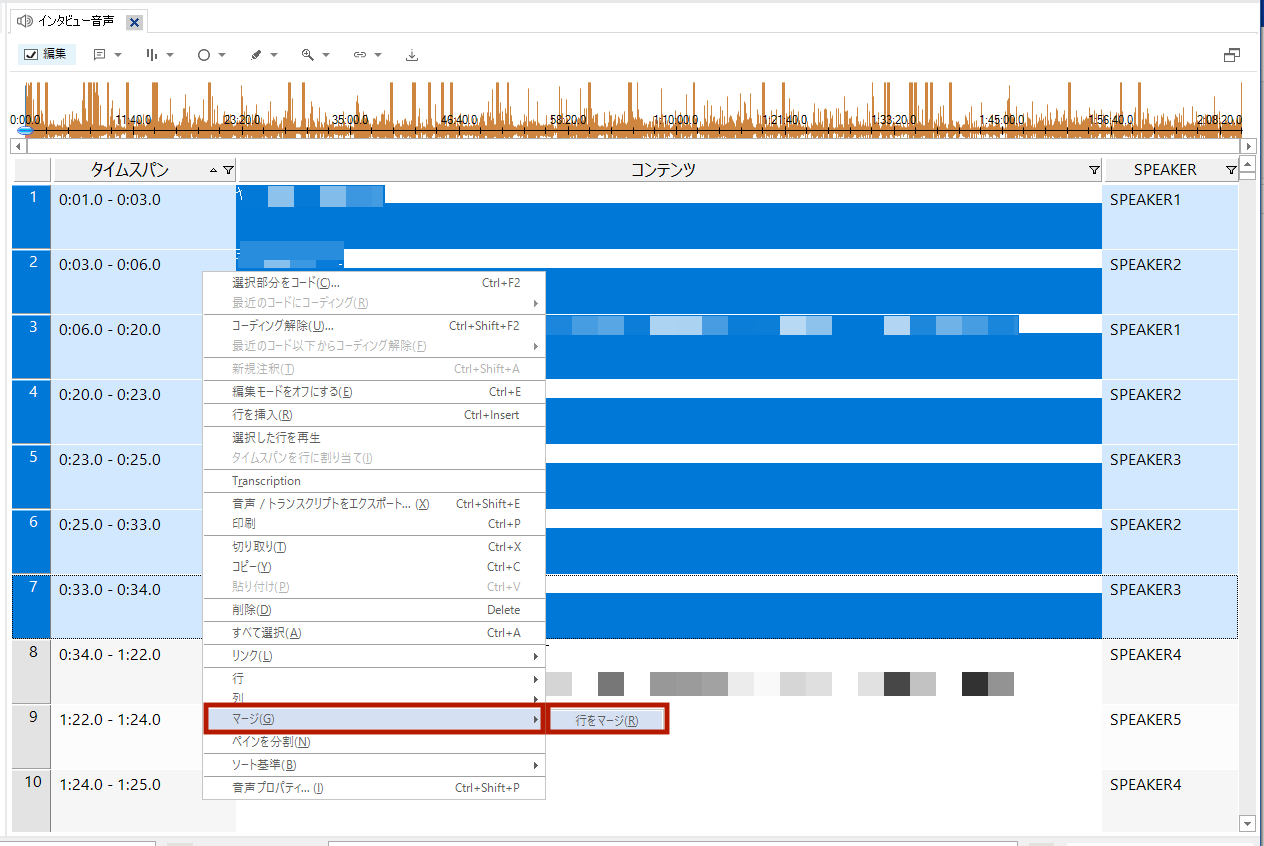
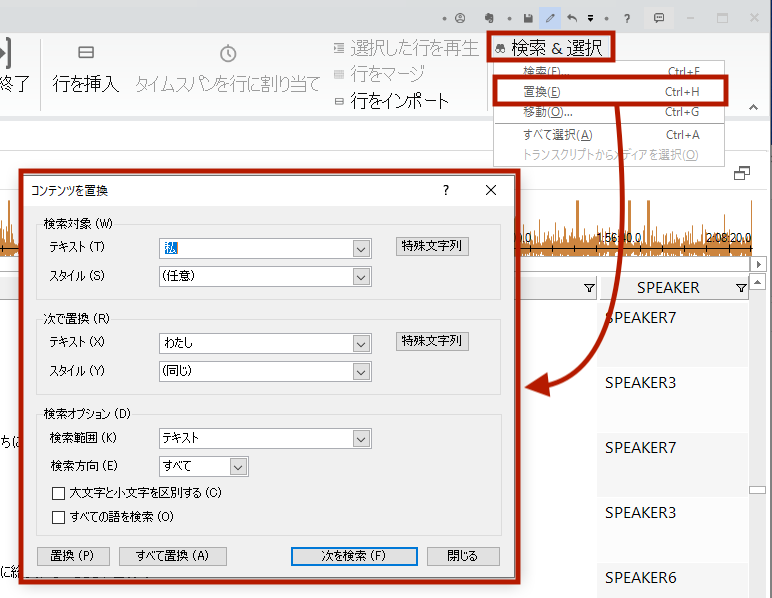
表記ゆれの統一には[置換]を使いました。
(NVivoにインポートする前にwordなどで行っても良いと思います)
これらの作業にはかなり時間がかかりました。マージした行の改行削除などかなり面倒で、ある程度編集したトランスクリプトを一旦エクスポートし、wordで改行削除や置換など済ませてから再度インポートし直すなど、試行錯誤の繰り返しとなってしまったことも原因の一つです。
また、音声認識の精度は、今回のファイルでは60~70%という印象でした。正確な部分も多い一方で、AIがパターンからの推測したためと思われる突拍子もない箇所も少なくありませんでした。
使用期限
NVivo Transcriptionは予め購入した時間を消費していくサービスです。購入した時間には使用期限がありますので、注意してください。詳細はNVivo Transcriptionまたは販売店のサイトなどでご確認ください。
今後の利用
NVivo Transcriptionを使うと、自分で書き起こすよりもタイピングは少なくて済みます。一方で、タイムススパンの調整など、タイピング以外の作業が多くなります。まだNVivoに慣れていない方には、タイムスパンの調整などは負担になる場合もありそうです。
あくまでも個人的な考えですが、自分が同席した一時間程度のインタビューであれば、自分で書き起こした方がストレスが少なくて済むように思いました。
(参考 – NVivo – ビデオや音声を書き起こす: NVivo 12の記事ですが、基本的な手順は現行バージョンでも同じです)
ただし、自分が同席していないものや長時間の場合は、まず下書きとしてNVivo Transcriptionで書き起こした方が楽かもしれません。正直な感想として、NVivo内でのトランスクリプト編集は、使いやすいとは言い難いところもあります。次に利用する機会があれば、先に手順を検討し、NVivo内の編集を最小限に抑えるようにしようと思っています。
購入済みの利用時間に余裕があれば、音声の一部分をNVivo Transcriptionで試してみてから方法を決めるのが良いかもしれません。
NVivo Transcriptionのメリットの一つは低料金・短時間という点だと思います。120分の書き起こしが30分もあれば完了し、料金も外注に比べればかなり抑えられる点は魅力的です。料金、時間、労力のバランスを考えながら、上手に利用できると良さそうですね。


